 BlackTopp Studios
BlackTopp Studios inc
This page will explain what the DAG FrameScheduler than explain how to use it.
This library tries to make writing multithreaded software easier by changing the kinds of primitives that multithreaded software is built upon. Several libraries before this have attempted this already. This library is different becuse it focuses on a specific kind of workload and provides the kinds of guarantees that the workload needs while sacrificing other guarantees that the workload does not need.
This attempts to provide a multithreading solution for workloads that must be run in many iterations in a given amount of realtime. Games are an ideal example. Every frame a video game must update physics simulations, make AI decisions, accept/interpret user input, enforce game rules, perform dynamic I/O and render it to the screen all while maintaining a smooth FrameRate and do that while minimizing drain to batteries on portable devices (sometimes without even knowing if the device is portable).
This library accomplishes those goals by removing the conventional mutlithreading primitives that so many developers have come to fear, loathe, or misunderstand. Mutexes, threads, memory fences, thread_local storage, atomic variables, and all the pitfalls that come with them are replaced by a small set of of primitives that provide all the required sophistication a typical multi-threaded application requires. It does this using a new kind of iWorkUnit, Double Buffering, a strong concept of dependencies and a FrameScheduler that uses heuristics to decide how to run it all without exposing needless complexity to the application developer.
The DAGFrameScheduler is a variation on a common multithreaded work queue. It seeks to avoid its pitfalls, such as non-determinism, thread contention, and lackluster scalability while keeping its advantages including simplicity, understandiblity, and low overhead.
With this algorithm very few, if any, calls will need to be made to the underlying system for synchronization of the actual work to be performed. Instead, this library will provide limited (not always, but for constistent workloads) deterministic ordering of iWorkUnit execution through a dependency feature. Having the knowledge that one iWorkUnit will complete after another allows for resources to be used without using expensive and complex synchronization mechansisms like mutexes, semaphores, or even an Atomic Compare And Swaps. These primitives are provided to allow use of this library in advanced ways for developers who are already familiar with multithreaded systems.
The internal work queue is not changed while a frame is executing. Because it is only read, each thread can pick its own work. Synchronization still needs to occur, but it has been moved onto each iWorkUnit amd is managed with atomic CPU operations. Like this, contention is less frequent occurring only when threads simultaneously attempt to start the same iWorkUnit. This consumes far less time because atomic operations are CPU instructions instead of Operating System calls. This is managed by the library, so individual iWorkUnits do not need to worry synchronization beyond telling each iWorkUnit about its data dependencies and making sure all the iWorkUnits are added to a FrameScheduler.
To understand why a new multithreading system is needed, it is helpful to look at other methods of threading that have been used in the past. This can give us an understanding of what they lack or how they aren't ideal for the kinds of work this algorithm is intended for. This overview is intentionally simplified. There are variations on many of these algorithms that can fix some of the problems presented. Despite these workarounds there are fundamental limitations that prevent these algorithms from being ideal for video games, simulations and similar tasks. These threading models aren't necessarily broken, as some of these clearly have a place in software development. Many of these require complex algorithms, require subtle knowledge, or simply aren't performant enough for realtime environments.
I will use charts that plot possible resource use of a computer across time. Generally time will run across the top as resources, usually CPUs, will run down one side. Most of these algorithms have a concept of tasks or workunits, which are just pieces of work with a distinct begining and end. The width of a piece of work loosely represents the execution time (the names are just for show and not related to anything real).
An application using this threading model is not actually multithreaded at all. However, It has been shown that software can run in a single and get good perfomance. This is the benchmark all other threading models get compared too.
There is a term, Speedup ( http://en.wikipedia.org/wiki/Speedup ), which is simply a comparison of the single threaded performance of an algorithm to the mutlithreaded performance. You simply determine how many times more work the multithreaded algorithm does in the same time, or how many times longer the single threaded algorithm takes to the same work. Ideally two threads will be twice as fast (speedup of 2x), and three thread would be three times as fast (3x speedup), and so; this is called linear speedup. In practice there is always some overhead in creating and synchronizing threads, so achieving linear speedup is difficult.
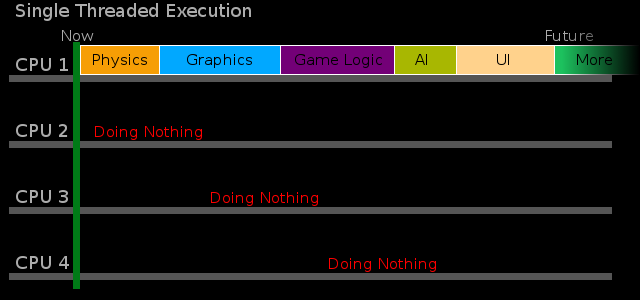
Sometimes someone means well and tries to increase the performance of a single threaded program and tries to add extra threads to increase performance. Sometimes this works really well and sometimes there is a marginal increase in performance or a significant increase in bugs. If that someone has a good plan then they can usually achieve close to the best speedup possible in the given situation. This is not easy and many cannot do this or do not want to invest the time it would take. If not carefully planned bugs like deadlock ( http://en.wikipedia.org/wiki/Deadlock ) and race conditions ( http://stackoverflow.com/questions/34510/what-is-a-race-condition ) can be introduced. Unfortunately no amount of testing can replace this careful planning. Without a complete understanding of how multithreaded software is assembled (a plan) it is not possible to prove that multithreaded software will not hang/freeze or that it will produce the correct results.
Software with no multithreading plan could have just about any kind of execution behavior. Usually unplanned software performs at least slightly better than single threaded versions of the software, but frequently does not utilize all the available resources. Generally performance does not scale well as unplanned software is run on more processors. Frequently, there is contention for a specific resource and a thread will wait for that resource longer than is actually needed.
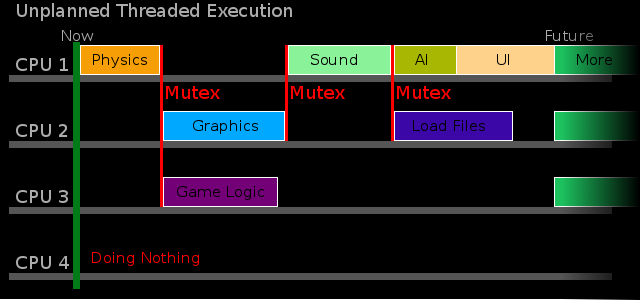
A common example of poor planning is the creation of one thread for each task in a game. Despite being conceptually simple, performance of systems designed this way is poor due to synchronization and complexities that synchronization requires.
Conventional work queues and thread pools are a well known and robust way to increase the throughput of of an application. These are ideal solutions for many systems, but not games.
In conventional workqueues all of the work is broken into a number of small thread-safe units. As these units are created they are stuffed into a queue and threads pull out units of work as it completes other units it has started. This simple plan has many advantages. If there is work to do then at least one thread will be doing some, and usually more threads will be working. This is good for games and the DAGFrameScheduler mimics it. If the kind of work is unknown when the software is written heuristics and runtime decisions can create the kind of units of work that are required. This is not the case with games and the others kinds of software this library caters to, so changes can be made that remove the problems this causes. One such drawback is that a given unit of work never knows if another is running or has completed, and must therefor make some pessimistic assumptions.
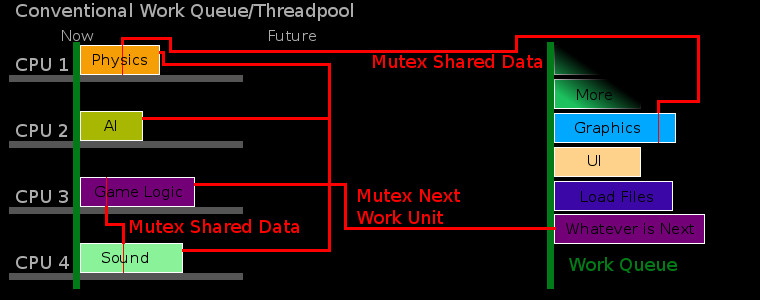
When first creating the DAGFrameScheduler it was called it "Dagma-CP". When describing it the phrase "Directed Acyclic Graph Minimal Assembly of Critical Path" was used. If you are lucky enough to knows what all those terms mean when assembled this way they are very descriptive. For rest of us the algorithm tries to determine what is the shortest way to execute the work in a minimalistic way using a mathematical graph. The graph is based on what work must done before other work each frame and executing it. All the work in this graph will have a location somewhere between the beginning and end, and will never circle around back so it can be called acyclic.
This algorithm was designed with practicality as the first priority. To accomodate and integrate with a variety of other algorithms and system a variety of Work Units are provided. New classes can be created that inherit from these to allow them to be in the scheduler where they will work best.
Once all the MonopolyWorkUnits are done then the FrameScheduler class instance spawns or activates a number of threads based on a simple heuristic. This heuristic is the way work units are sorted in preparation for execution. To understand how these are sorted, the dependency system needs to be understood.
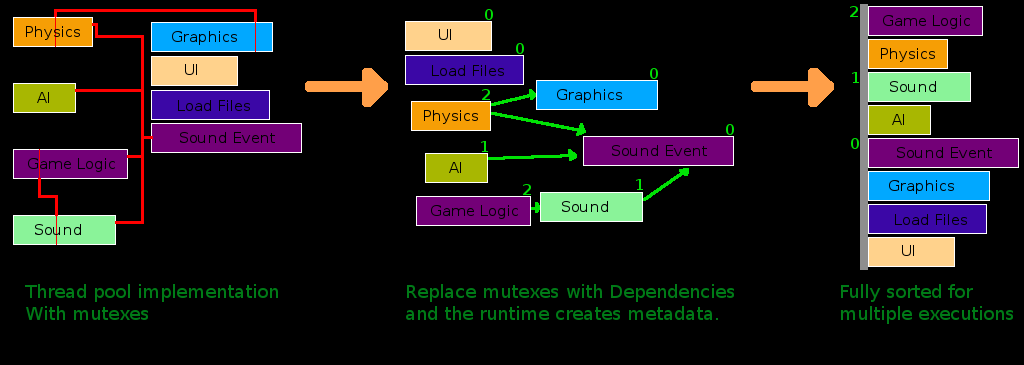
Most other work queues do not provide any guarantee about the order work will be executed in. This means that each piece of work must ensure its own data integrity using synchronization primitives like mutexes and semaphores to protect from being corrupted by multithread access. In most cases these should be removed and one of any two work units that must read/write the data must depend on the other. This allows the code in the workunits to be very simple even if it needs to use a great deal of data other work units may also consume or produce.
Once all the dependencies are in place for any synchronization that has been removed, a FrameScheduler can be created and started. At runtime this creates a reverse dependency graph, a DependentGraph. This is used to determine which work units are the most depended upon. For each work unit a simple count of how many work units cannot start until has been completed is generated. The higher this number the earlier the work unit will be executed in a frame. Additionally workunits that take longer to execute will be prioritized ahead of work units that are faster.
Here is a chart that provides an example of this re-factoring and the runtime sorting process:
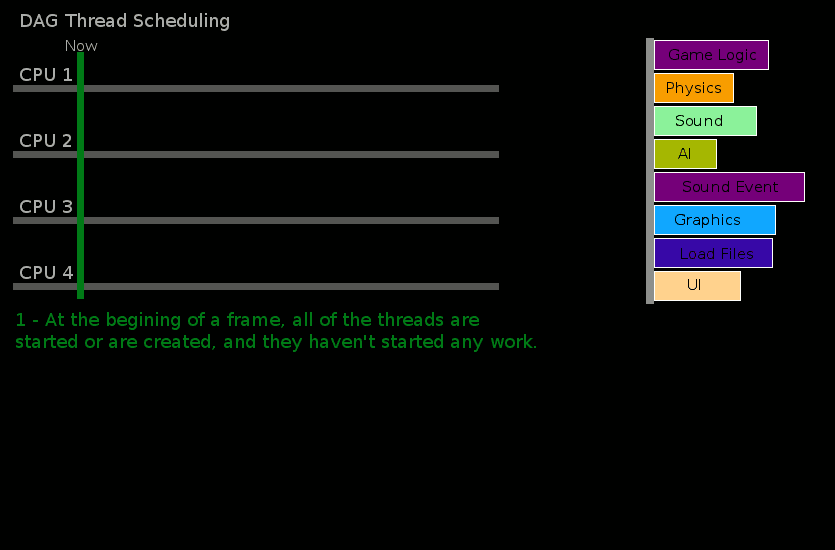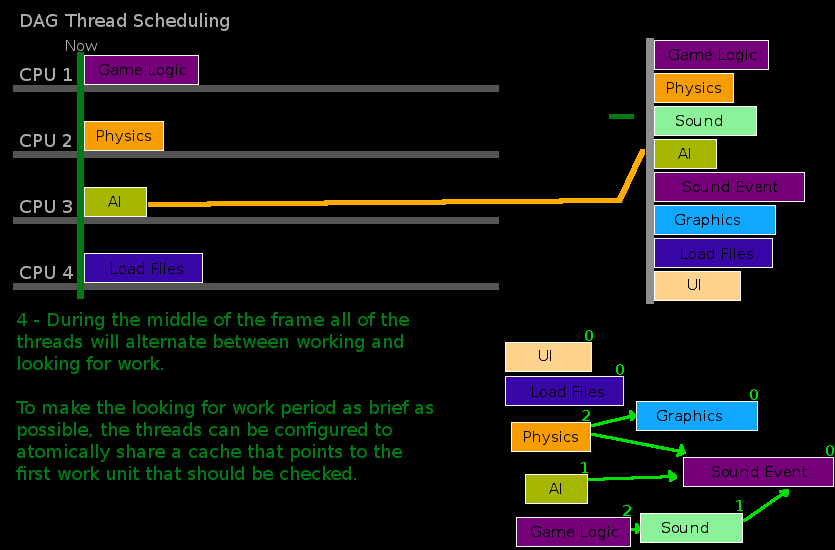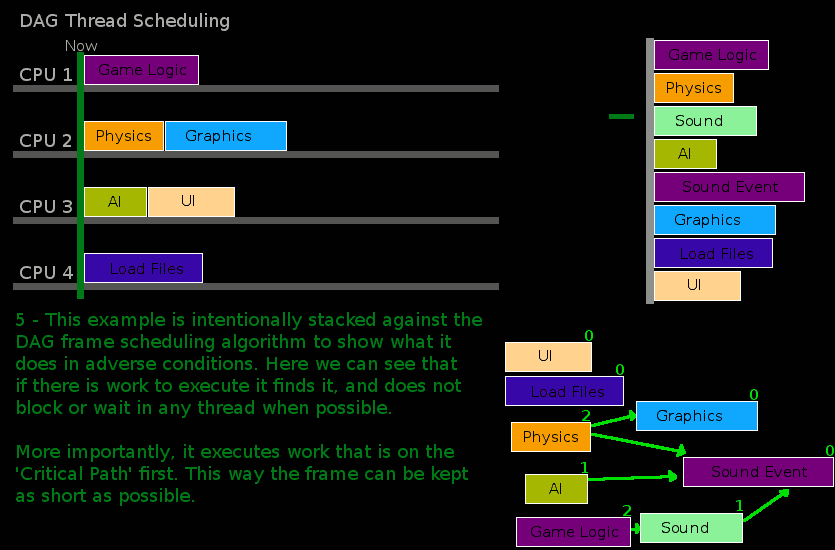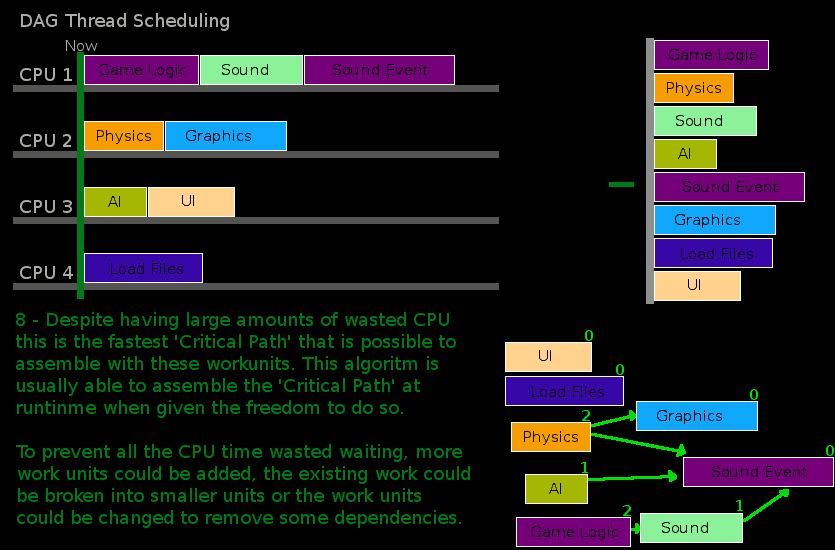
Some work must be run on specific threads, such as calls to underlying devices (for example, graphics cards using Directx or OpenGL). These iWorkUnits are put into a different listing where only the main thread will attempt to execute them. Other than running these, and running these first, the behavior of the main thread is very similar to other threads.
Even much of the FrameScheduler's work is performed in iWorkUnits, such as log aggregation and Sorting the work listing. iAsynchronousWorkUnits continue to run in a thread beyond normal scheduling and are intended to consume fewer CPU resources and more IO resources. For example loading a large file or listening for network traffic. These will be normal iWorkUnits in most regards and will check on the asynchronous tasks they manage each frame when they run as a normally scheduled.
If a thread runs out of work because all the work is completed the frame will pause until it should start again the next frame. This pause length is calulated using a runtime configurable value on the FrameScheduler. If a thread has checked every iWorkUnit and some are still not executing, but could not be started because of incomplete dependencies the thread will simply iterate over every iWorkUnit in the FrameScheduler until the dependencies of one are met and allows one to be executed. This implicitly guarantees that at least one thread will always do work, and if dependencies chains are kept short then it is more likely that several threads will advance.
When FrameScheduler::DoOneFrame() is called several things happen. All work units are executed, all threads are paused until the this frame has consumed the amount of time it should, and the timer is restarted for the next frame.
This process is actually divided into six steps. The function FrameScheduler::DoOneFrame() simply calls the following functions:
The function FrameScheduler::RunAllMonopolies() simply iterates through all the MonopolyWorkUnit that have been added with FrameScheduler::AddWorkUnitMonopoly(). It does this in no specific order.
In general MonopolyWorkUnits can be expected to use all available CPU resources. Other threads should not be executed in general.
The function FrameScheduler::CreateThreads() Creates enough threads to get to the amount set by FrameScheduler::SetThreadCount() . Depending on how this library is configured this could mean either creating that many threads each frame or creating additional threads only if this changed.
Regardless of the amount of threads created, all but one of them will start executing work units as described in the section The Algorithm. This will execute as much work as possible (work units with affinity can affect how much work can be done with out waiting) that was added by FrameScheduler::AddWorkUnitMain. If there is only one thread, the main thread, then this will return immediately and no work will be done.
The call to FrameScheduler::RunMainThreadWork() will start the main thread executing work units. This is the call that executes work units added with FrameScheduler::AddWorkUnitAffinity.
If you have single thread work that is not part of a work unit and will not interfere with and work units execution then you can run it before calling this. Be careful when doing this, if there are any work units that depend on work units with affinity then they will not be able to start until some point after this is called.
Once every work unit has started this call can return. This does not mean every work unit is complete, though every work unit with affinity will be complete. There could be work in other threads still executing. This is another good point to run work that is single threaded and won't interfere with workunits that could be executing.
If you must execute something that could interfere (write to anything they could read or write) with work units, you should do that after FrameScheduler::JoinAllThreads() is called. This joins, destroys, or otherwise cleans up the threads the scheduler has used depending on how this library is configured.
All the work units are marked as complete and need to be reset with FrameScheduler::ResetAllWorkUnits() to be used by the next frame. This simply iterates over each work unit resetting their status. A potential future optimization could run this as a multithreaded monopoly instead.
The final step is to wait until the next frame should begin. To do this tracking the begining of of each frame is required. The value in FrameScheduler::CurrentFrameStart is on FrameScheduler construction to the current time, and reset every to the current time when FrameScheduler::WaitUntilNextFrame() is called. The value set by FrameScheduler::SetFrameRate() is used to calculate the desired length of a frame in microseconds. If the begining of the next frame has not been reached, then this function will sleep the scheduler until the next frame should begin. To compensate for systems with an imprecise sleep mechanism (or timing mechanism) an internal FrameScheduler::TimingCostAllowance is tracked that averages the effects of imprecision across multiple frames to prevent roundings errors from consistently lengthening of shortening frames.
Still in progress. In the meantime please peruse the unit test source directory for examples.
There are some fundamental differences in the DAGFrameSchedulers coded when compared to the code in the Mezzanine.
The most obvious is the usage of exceptions. The DAGFrameScheduler does not use Exceptions in any way. There are a few reasons for this.
There are 3 directories with code that overlap in the Mezzanine and in the DAGFrameScheduler. Code That lies outside these directories is independent of the other project. The entire FrameScheduler library loosely correlates with the Mezzanine::Threading namespace. Then there is the tests and test framework source code. Presuming you have used git to clone both repositories to ~/Code/Mezzanine/UnitTests/src <=> ~/Code/DAGFrameScheduler/testframework
~/Code/Mezzanine/Mezzanine/src/Threading <=> ~/Code/DAGFrameScheduler/src
~/Code/Mezzanine/UnitTests/tests <=> ~/Code/DAGFrameScheduler/tests
For simplicity when BlackTopp Studios Inc merge changes a graphical merge tool capable of directory merges is used to manually move changes between corresponding directories. Winmerge and Meld (Quite possibly the prettiest merge tool ever created) are two great examples of tools for doing this.
 1.8.9.1. Thanks to the
Open Icon Library
for help with some of the icons.
1.8.9.1. Thanks to the
Open Icon Library
for help with some of the icons.

