 BlackTopp Studios
BlackTopp Studios inc
This will describe how to use the XML components of the Mezzanine
Mezzanine::xml is a light-weight C++ XML processing library. It consists of a DOM-like interface with rich traversal/modification capabilities, an extremely fast XML parser which constructs the DOM tree from an XML file/buffer, and an XPath 1.0 implementation for complex data-driven tree queries. Unicode is fully support via UF8 in 8bit characters and for conversions between different Unicode encodings (which happen automatically during parsing/saving).
Mezzanine::xml enables very fast, convenient and memory-efficient XML document processing. However, since Mezzanine::xml has a DOM parser, it can't process XML documents that do not fit in memory; also the parser is a non-validating one, so if you need DTD or XML Schema validation, the XML parser is not for you.
If you believe you've found a bug in Mezzanine::xml (bugs include compilation problems (errors/warnings), crashes, performance degradation and incorrect behavior), please contact Blacktopp Studios Inc ( http://www.blacktoppstudios.com/ ) . We check the the Forums ( http://www.blacktoppstudios.com/?page_id=753 ) and items sent by our contact form ( http://www.blacktoppstudios.com/?page_id=33 ) regularly. Be sure to include the relevant information so that the bug can be reproduced: the version of Mezzanine::xml, compiler version and target architecture, the code that uses Mezzanine::xml and exhibits the bug, etc.
Feature requests can be reported the same way as bugs, so if you're missing some functionality in Mezzanine::xml or if the API is rough in some places and you can suggest an improvement, please let us know. However, please note that there are many factors when considering API changes (compatibility with previous versions, API redundancy, etc.).
If you have a contribution to Mezzanine::xml, such as build script for some build system/IDE, or a well-designed set of helper functions, or a binding to some language other than C++, please let us know. You can include the relevant patches as issue attachments. We will have to communicate on the Licensing terms of your contribution though.
If the provided methods of contact have an issue or not possible due to privacy or other concerns, you can contact the Mezzanine::xml author ( toppij@blacktoppstudios.com ) or pugixml author ( arseny.kapoulkine@gmail.com ) by e-mail directly. If you have an issue that pertains to pugixml and not Mezzanine::xml you can visit the pugixml issue submission form ( http://code.google.com/p/pugixml/issues/entry ) of the pugixml feature request form ( http://code.google.com/p/pugixml/issues/entry?template=Feature%20request ).
Mezzanine::xml and pugixml could not be developed without the help from many people; some of them are listed in this section. If you've played a part in Mezzanine::xml or pugixml development and you can not find yourself on this list, I'm truly sorry; please send me an e-mail ( toppij@blacktoppstudios.com ) so I can fix this.
Thanks to Arseny Kapoulkine for pugixml parser, which was used as a basis for Mezzanine::xml.
Thanks to Kristen Wegner for pugxml parser, which was used as a basis for pugixml.
Thanks to Neville Franks for contributions to pugxml parser.
Thanks to Artyom Palvelev for suggesting a lazy gap contraction approach.
Thanks to Vyacheslav Egorov for documentation proofreading.
With written permission as per The original pugixml license we he sublicensed Mezzanine::xml under the GPL Version 3. In short This allows you to use Mezzanine::xml however you like with a few restrictions. If you change Mezzanine::xml you need to make the changes publically available. If you make software using Mezzanine::xml you need to make the source code publicly available. You may not use and Digital Rights Management (DRM) software to limit how others use the combined work you make. You can sell resulting works, but not through a digital distribution store that uses DRM.
Mezzanine::xml stores XML data in DOM-like way: the entire XML document (both document structure and element data) is stored in memory as a tree. The tree can be loaded from a character stream (file, string, C++ I/O stream), then traversed with the special API or XPath expressions. The whole tree is mutable: both node structure and node/attribute data can be changed at any time. Finally, the result of document transformations can be saved to a character stream (file, C++ I/O stream or custom transport).
The XML document is represented with a tree data structure. The root of the tree is the document itself, which corresponds to C++ type Mezzanine::XML::Document. A Document has one or more child nodes, which correspond to C++ type Mezzanine::XML::Node. Nodes have different types; depending on a type, a node can have a collection of child nodes, a collection of attributes, which correspond to C++ type Mezzanine::XML::Attribute, and some additional data (i.e. Name).
The tree nodes can be of one of the following types (which together form the enumeration Mezzanine::XML::NodeType):
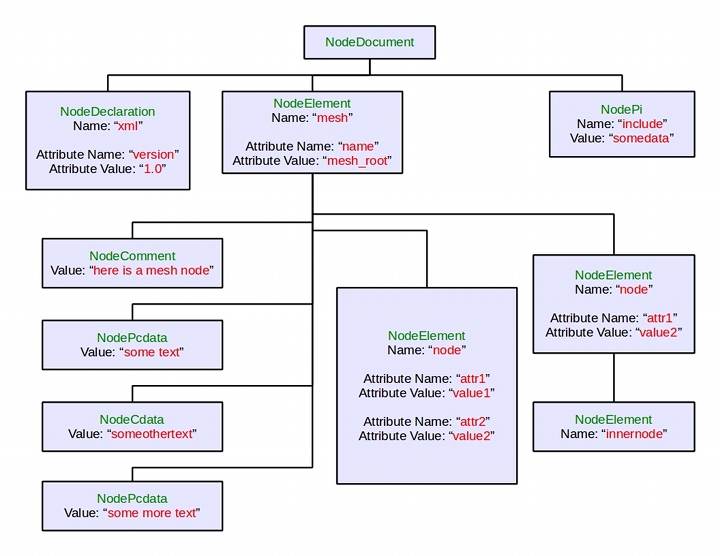
Despite the fact that there are several node types, there are only three C++ classes representing the tree (Mezzanine::XML::Document, Mezzanine::XML::Node, Mezzanine::XML::Attribute); some operations on Mezzanine::XML::Node are only valid for certain node types. The classes are described below.
Mezzanine::XML::Document is the owner of the entire document structure; it is a non-copyable class. The interface of Mezzanine::XML::Document consists of loading functions ( see Loading Documents ), saving functions ( see Saving Documents ) and the entire interface of Mezzanine::XML::Node, which allows for document inspection and/or modification. Note that while Mezzanine::XML::Document is a sub-class of Mezzanine::XML::Node, Mezzanine::XML::Node is not a polymorphic type; the inheritance is present only to simplify usage. Alternatively you can use the Mezzanine::XML::Document::DocumentElement function to get the element node that's the immediate child of the document.
Default constructor of Mezzanine::XML::Document initializes the document to the tree with only a root node ( Mezzanine::XML::Document node). You can then populate it with data using either tree modification functions or loading functions; all loading functions destroy the previous tree with all occupied memory, which puts existing node/attribute handles for this document to invalid state. If you want to destroy the previous tree, you can use the Mezzanine::XML::Document::Reset function; it destroys the tree and replaces it with either an empty one or a copy of the specified document. Destructor of Mezzanine::XML::Document also destroys the tree, thus the lifetime of the document object should exceed the lifetimes of any node/attribute handles that point to the tree.
Mezzanine::XML::Node is the handle to a document node; it can point to any node in the document, including the document node itself. There is a common interface for nodes of all types; the actual node type can be queried via the Mezzanine::XML::Node::Type() method. Note that Mezzanine::XML::Node is only a handle to the actual node, not the node itself - you can have several Mezzanine::XML::node handles pointing to the same underlying object. Destroying Mezzanine::XML::Node handle does not destroy the node and does not remove it from the tree. The size of Mezzanine::XML::Node is equal to that of a pointer, so it is nothing more than a lightweight wrapper around a pointer; you can safely pass or return Mezzanine::xml:Node objects by value without additional overhead.
There is a special value of Mezzanine::XML::Node type, known as null node or empty node (such nodes have type NodeNull). It does not correspond to any node in any document, and thus resembles null pointer. However, all operations are defined on empty nodes; generally the operations don't do anything and return empty nodes/attributes or empty strings as their result (see documentation for specific functions for more detailed information). This is useful for chaining calls; i.e. you can get the grandparent of a node like so: node.GetParent().GetParent(); if a node is a null node or it does not have a parent, the first Node::GetParent() call returns null node; the second GetParent() call then also returns null node, which can make error handling easier.
Mezzanine::XML::Attribute is a handle to an XML attribute; it has the same semantics as Mezzanine::XML::Node, i.e. there can be several Mezzanine::XML::Attribute handles pointing to the same underlying object and there is a special null attribute value, which propagates to function results.
Both Mezzanine::XML::Node and Mezzanine::XML::Attribute have the default constructor which initializes them to null objects.
Mezzanine::XML::Node and Mezzanine::XML::Attribute try to behave like pointers, that is, they can be compared with other objects of the same type, making it possible to use them as keys in associative containers. All handles to the same underlying object are equal, and any two handles to different underlying objects are not equal. Null handles only compare as equal to themselves. The result of relational comparison can not be reliably determined from the order of nodes in file or in any other way. Do not use relational comparison operators except for search optimization (i.e. associative container keys).
If you want to use Mezzanine::XML::Node or Mezzanine::XML::Attribute objects as keys in hash-based associative containers, you can use the Mezzanine::XML::Node::HashValue or Mezzanine::XML::Attribute::HashValue member functions. They return the hash values that are guaranteed to be the same for all handles to the same underlying object. The hash value for null handles is 0.
Finally handles can be implicitly cast to boolean-like objects, so that you can test if the node/attribute is empty with the following code: if (node) { ... } or if (!node) { ... } else { ... }. Alternatively you can check if a given Node/Attribute handle is null by calling the Mezzanine::XML::Attribute::Empty or the Mezzanine::XML::Node::Empty Methods.
Nodes and attributes do not exist without a document tree, so you can't create them without adding them to some document. Once underlying node/attribute objects are destroyed, the handles to those objects become invalid. While this means that destruction of the entire tree invalidates all node/attribute handles, it also means that destroying a subtree ( by calling Mezzanine::XML::Node::RemoveChild ) or removing an attribute invalidates the corresponding handles. There is no way to check handle validity; you have to ensure correctness through external mechanisms.
Almost all functions in Mezzanine::xml have the following thread-safety guarantees:
Concurrent modification and traversing of a single tree requires synchronization, for example via reader-writer lock. Modification includes altering document structure and altering individual node/attribute data, i.e. changing names/values.
The only exception is Mezzanine::XML::SetMemory_management_functions; it modifies global variables and as such is not thread-safe. Its usage policy has more restrictions, see Custom memory allocation/deallocation functions .
With the exception of XPath, Mezzanine::xml itself does not throw any exceptions. Additionally, most Mezzanine::xml functions have a no-throw exception guarantee.
This is not applicable to functions that operate on STL strings or IOstreams; such functions have either strong guarantee (functions that operate on strings) or basic guarantee (functions that operate on streams). Also functions that call user-defined callbacks (i.e. Mezzanine::XML::Node::Traverse or Mezzanine::XML::Node::FindNode) do not provide any exception guarantees beyond the ones provided by the callback.
XPath functions may throw Mezzanine::XML::XPathException on parsing errors; also, XPath functions may throw std::bad_alloc in low memory conditions. Still, XPath functions provide strong exception guarantee.
Mezzanine::xml requests the memory needed for document storage in big chunks, and allocates document data inside those chunks. This section discusses replacing functions used for chunk allocation and internal memory management implementation.
All memory for tree structure, tree data and XPath objects is allocated via globally specified functions, which default to malloc/free. You can set your own allocation functions with Mezzanine::XML::SetMemory_management_functions function. The function interfaces are the same as that of malloc/free:
You can use the following accessor functions to change or get current memory management functions:
Allocation function is called with the size (in bytes) as an argument and should return a pointer to a memory block with alignment that is suitable for storage of primitive types (usually a maximum of void* and double types alignment is sufficient) and size that is greater than or equal to the requested one. If the allocation fails, the function has to return null pointer (throwing an exception from allocation function results in undefined behavior).
Deallocation function is called with the pointer that was returned by some call to allocation function; it is never called with a null pointer. If memory management functions are not thread-safe, library thread safety is not guaranteed.
When setting new memory management functions, care must be taken to make sure that there are no live Mezzanine::xml objects. Otherwise when the objects are destroyed, the new deallocation function will be called with the memory obtained by the old allocation function, resulting in undefined behavior.
Constructing a document object using the default constructor does not result in any allocations; document node is stored inside the Mezzanine::XML::Document object
When the document is loaded from file/buffer, unless an inplace loading function is used ( see Loading document from memory ), a complete copy of character stream is made; all names/values of nodes and attributes are allocated in this buffer. This buffer is allocated via a single large allocation and is only freed when document memory is reclaimed (i.e. if the Mezzanine::XML::Document object is destroyed or if another document is loaded in the same object). Also when loading from file or stream, an additional large allocation may be performed if encoding conversion is required; a temporary buffer is allocated, and it is freed before load function returns.
All additional memory, such as memory for document structure (node/attribute objects) and memory for node/attribute names/values is allocated in pages on the order of 32 kilobytes; actual objects are allocated inside the pages using a memory management scheme optimized for fast allocation/deallocation of many small objects. Because of the scheme specifics, the pages are only destroyed if all objects inside them are destroyed; also, generally destroying an object does not mean that subsequent object creation will reuse the same memory. This means that it is possible to devise a usage scheme which will lead to higher memory usage than expected; one example is adding a lot of nodes, and them removing all even numbered ones; not a single page is reclaimed in the process. However this is an example specifically crafted to produce unsatisfying behavior; in all practical usage scenarios the memory consumption is less than that of a general-purpose allocator because allocation meta-data is very small in size.
Mezzanine::xml provides several functions for loading XML data from various places - files, C++ iostreams, memory buffers. All functions use an extremely fast non-validating parser. This parser is not fully W3C conformant - it can load any valid XML document, but does not perform some well-formedness checks. While considerable effort is made to reject invalid XML documents, some validation is not performed for performance reasons. Also some XML transformations (i.e. EOL handling or attribute value normalization) can impact parsing speed and thus can be disabled. However for vast majority of XML documents there is no performance difference between different parsing options. Parsing options also control whether certain XML nodes are parsed; see Parsing Options for more information.
XML data is always converted to internal character format before parsing. Mezzanine::xml supports all popular Unicode encodings (UTF-8, UTF-16 (big and little endian), UTF-32 (big and little endian); UCS-2 is naturally supported since it's a strict subset of UTF-16) and handles all encoding conversions automatically. Unless explicit encoding is specified, loading functions perform automatic encoding detection based on first few characters of XML data, so in almost all cases you do not have to specify document encoding. Encoding conversion is described in more detail in Encodings.
The most common source of XML data is files; Mezzanine::xml provides dedicated functions for loading an XML document from file:
These functions accept the file path as its first argument, and also two optional arguments, which specify parsing options (see Parsing options) and input data encoding ( see Encodings ). The path has the target operating system format, so it can be a relative or absolute one, it should have the delimiters of the target system, it should have the exact case if the target file system is case-sensitive, and is subject to any other restrictions of the underlying filesystem.
File path is passed to the system file opening function as is in case of the first function (which accepts const char* path); the second function either uses a special file opening function if it is provided by the runtime library or converts the path to UTF-8 and uses the system file opening function.
Document::LoadFile destroys the existing document tree and then tries to load the new tree from the specified file. The result of the operation is returned in an Mezzanine::XML::ParseResult object; this object contains the operation status and the related information (i.e. last successfully parsed position in the input file, if parsing fails). See Handling Parsing Errors for error handling details.
This is an example of loading XML document from file:
Sometimes XML data should be loaded from some other source than a file, i.e. HTTP URL; also you may want to load XML data from file using non-standard functions, i.e. to use your virtual file system facilities or to load XML from gzip-compressed files. All these scenarios require loading document from memory. First you should prepare a contiguous memory block with all XML data; then you have to invoke one of buffer loading functions. These functions will handle the necessary encoding conversions, if any, and then will parse the data into the corresponding XML tree. There are several buffer loading functions, which differ in the behavior and thus in performance/memory usage:
All functions accept the buffer which is represented by a pointer to XML data, contents, and data size in bytes. Also there are two optional arguments, which specify parsing options ( see Parsing Options ) and input data encoding ( see Encodings ). The buffer does not have to be zero-terminated.
Mezzanine::XML::Document::LoadBuffer function works with immutable buffer - it does not ever modify the buffer. Because of this restriction it has to create a private buffer and copy XML data to it before parsing (applying encoding conversions if necessary). This copy operation carries a performance penalty, so inplace functions are provided - Mezzanine::XML::Document::LoadBufferInplace and Mezzanine::XML::Document::LoadBufferInplaceOwn store the document data in the buffer, modifying it in the process. In order for the document to stay valid, you have to make sure that the buffer's lifetime exceeds that of the tree if you're using inplace functions. In addition to that, Mezzanine::XML::Document::LoadBufferInplace does not assume ownership of the buffer, so you'll have to destroy it yourself; Mezzanine::XML::Document::LoadBufferInplaceOwn assumes ownership of the buffer and destroys it once it is not needed. This means that if you're using Mezzanine::XML::Document::LoadBufferInplaceOwn, you have to allocate memory with Mezzanine::xml allocation function ( Not recomended, the Allocation API may be getting updates in the near future ).
The best way from the performance/memory point of view is to load document using Mezzanine::XML::Document::LoadBufferInplaceOwn; this function has maximum control of the buffer with XML data so it is able to avoid redundant copies and reduce peak memory usage while parsing. However, this is not recommendeded unless you have to load the document from memory and performance is critical. Once the memory portion of the API has stabilized this will become the ideal
There is also a simple helper function for cases when you want to load the XML document from null-terminated character string:
It is equivalent to calling Mezzanine::XML::Document::LoadBuffer with size being either strlen(contents) or wcslen(contents) * sizeof(wchar_t), depending on the character type. This function assumes native encoding for input data, so it does not do any encoding conversion. In general, this function is fine for loading small documents from string literals, but has more overhead and less functionality than the buffer loading functions.
This is an example of loading XML document from memory using LoadBuffer:
This is an example of loading XML document from memory using LoadBufferInplace:
This is an example of loading XML document from memory using Load and a string literal:
To enhance interoperability, Mezzanine::xml provides functions for loading document from any object which implements C++ std::istream interface. This allows you to load documents from any standard C++ stream (i.e. file stream) or any third-party compliant implementation (i.e. Boost Iostreams). There are two functions, one works with narrow character streams, another handles wide character ones:
Mezzanine::XML::Document::Load with std::istream argument loads the document from stream from the current read position to the end, treating the stream contents as a byte stream of the specified encoding (with encoding autodetection as necessary). Thus calling Mezzanine::XML::Document::Load on an opened std::ifstream object is equivalent to calling Mezzanine::XML::Document::LoadFile.
Mezzanine::XML::Document::Load with std::wstream argument treats the stream contents as a wide character stream ( encoding is always Encoding::Encodingwchar_t ). Because of this, using Mezzanine::XML::Document::LoadFile with wide character streams requires careful (usually platform-specific) stream setup (i.e. using the imbue function). Generally use of wide streams is discouraged, however it provides you the ability to load documents from non-Unicode encodings, i.e. you can load Shift-JIS encoded data if you set the correct locale.
This is a simple example of loading XML document from a file using streams read:
Stream loading requires working seek/tell functions and therefore may fail when used with some stream implementations like gzstream.
All document loading functions return the parsing result via Mezzanine::XML::ParseResult object. It contains parsing status, the offset of last successfully parsed character from the beginning of the source stream, and the encoding of the source stream.
Parsing status is represented as the Mezzanine::XML::ParseStatus enumeration and can be one of the following:
Mezzanine::XML::ParseResult::Description member function can be used to convert parsing status to a string; the returned message is always in English, so you'll have to write your own function if you need a localized string. However please note that the exact messages returned by the Description() function may change from version to version, so any complex status handling should be based on the Status value.
If parsing failed because the source data was not a valid XML, the resulting tree is not destroyed - despite the fact that load function returns error, you can use the part of the tree that was successfully parsed. Obviously, the last element may have an unexpected name/value; for example, if the attribute value does not end with the necessary quotation mark, like in <node attr="value>some data</node> example, the value of attribute attr will contain the string "value>some data</node>".
In addition to the Status code, Mezzanine::XML::ParseResult has an Offset member, which contains the offset of last successfully parsed character if parsing failed because of an error in source data; otherwise offset is 0. For parsing efficiency reasons, Mezzanine::xml does not track the current line during parsing; this offset is in units of Mezzanine::XML::char_t (bytes for character mode, wide characters for wide character mode). Many text editors support 'Go To Position' feature - you can use it to locate the exact error position. Alternatively, if you're loading the document from memory, you can display the error chunk along with the error description.
Mezzanine::XML::ParseResult also has a DocumentEncoding member, which can be used to check that the source data encoding was correctly guessed. It is equal to the exact encoding used during parsing (i.e. with the exact endianness); see Encodings for more information.
A Mezzanine::XML::ParseResult object can be implicitly converted to bool; if you do not want to handle parsing errors thoroughly, you can just check the return value of load functions as if it was a bool: if (doc.load_file("file.xml")) { //on Successful parse } else { //on failed parse }. A True is returned if parsing was successful.
This is an example of handling loading errors:
All document loading functions accept the optional parameter options. This is a bitmask that customizes the parsing process: you can select the node types that are parsed and various transformations that are performed with the XML text. Disabling certain transformations can improve parsing performance for some documents; however, the code for all transformations is very well optimized, and thus the majority of documents won't get any performance benefit. As a general rule, only modify parsing flags if you want to get some nodes in the document that are excluded by default (i.e. declaration or comment nodes).
These flags control the resulting tree contents:
These flags control the transformation of tree element contents:
Additionally there are three predefined option masks:
This is an example of using different parsing options:
Mezzanine::xml supports all popular Unicode encodings (UTF-8, UTF-16 (big and little endian), UTF-32 (big and little endian); UCS-2 is naturally supported since it's a strict subset of UTF-16) and handles all encoding conversions. Most loading functions accept the optional parameter encoding. This is a value of enumeration type Mezzanine::XML::Encoding, that can have the following values:
The algorithm used for EncodingAuto correctly detects any supported Unicode encoding for all well-formed XML documents (since they start with document declaration) and for all other XML documents that start with <; if your XML document does not start with < and has encoding that is different from UTF-8, use the specific encoding.
Mezzanine::xml is not fully W3C conformant - it can load any valid XML document, but does not perform some well-formedness checks. While considerable effort is made to reject invalid XML documents, some validation is not performed because of performance reasons.
There is only one non-conformant behavior when dealing with valid XML documents, Mezzanine::xml does not use information supplied in document type declaration for parsing. This means that entities declared in DOCTYPE are not expanded, and all attribute/PCDATA values are always processed in a uniform way that depends only on parsing options.
As for rejecting invalid XML documents, there are a number of incompatibilities with W3C specification, including:
Mezzanine::xml features an extensive interface for getting various types of data from the document and for traversing the document. This section provides documentation for all such functions that do not modify the tree except for XPath-related functions; see XPath for XPath reference. As discussed in C++ interface, there are two types of handles to tree data - Mezzanine::XML::Node and Mezzanine::XML::Attribute. The handles have special null (empty) values which propagate through various functions and thus are useful for writing more concise code; see C++ interface for details. The documentation in this section will explicitly state the results of all function in case of null inputs.
The internal representation of the document is a tree, where each node has a list of child nodes (the order of children corresponds to their order in the XML representation), additionally element nodes have a list of attributes, which is also ordered. Several functions are provided in order to let you get from one node in the tree to the other. These functions roughly correspond to the internal representation, and thus are usually building blocks for other methods of traversing (i.e. XPath traversals are based on these functions).
The GetParent function returns the node's parent; all non-null nodes except the document have non-null parent. GetFirstChild and GetLastChild return the first and last child of the node, respectively; note that only document nodes and element nodes can have non-empty child node list. If node has no children, both functions return null nodes. GetNextSibling and GetPreviousSibling return the node that's immediately to the right/left of this node in the children list, respectively - for example, in <a/> <b/> <c/>, calling GetNextSibling for a handle that points to <b/> results in a handle pointing to <c/>, and calling GetPreviousSibling results in handle pointing to <a/>. If node does not have next/previous sibling (this happens if it is the last/first node in the list, respectively), the functions return null nodes. GetFirstAttribute, GetLastAttribute, GetNextAttribute and GetPreviousAttribute functions behave similarly to the corresponding child node functions and allow to iterate through attribute list in the same way.
Calling any of the functions above on the null handle results in a null handle - i.e. node.GetFirstChild().GetNextSibling() returns the second child of node, and null handle if node is null, has no children at all or if it has only one child node.
With these functions, you can iterate through all child nodes and display all attributes like this:
Apart from structural information (parent, child nodes, attributes), nodes can have name and value, both of which are strings. Depending on node type, name or value may be absent. NodeDocument nodes do not have a name or value, NodeElement and NodeType::NodeDeclaration nodes always have a name but never have a value, NodeType::NodePcdata, NodeType::NodeCdata, NodeType::NodeComment and NodeType::NodeDocType nodes never have a name but always have a value (it may be empty though), NodeType::NodePi nodes always have a name and a value (again, value may be empty). In order to get node's name or value, you can use the following functions:
In case node does not have a name or value or if the node handle is null, both functions return empty strings - they never return null pointers.
It is common to store data as text contents of some node - i.e. <node> <description> This is a node </description> </node>. In this case, <description> node does not have a value, but instead has a child of type NodeType::NodePcdata with value "This is a node". Mezzanine::xml provides two helper functions to parse such data:
ChildValue() returns the value of the first child with type NodeType::NodePcdata or NodeType::NodeCdata; ChildValue(Name) is a simple wrapper for Child(Name).ChildValue(). For the above example, calling node.ChildValue("description") and description.ChildValue() will both produce string "This is a node". If there is no child with relevant type, or if the handle is null, ChildValue functions return empty string.
There is an example of using some of these functions at the end of the next section.
All attributes have name and value, both of which are strings (value may be empty). There are two corresponding accessors:
In case the attribute handle is null, both functions return empty strings - they never return null pointers.
In many cases attribute values have types that are not strings - i.e. an attribute may always contain values that should be treated as integers, despite the fact that they are represented as strings in XML. Mezzanine::xml provides several accessors that convert attribute value to some other type:
AsDouble, AsFloat, AsInt, AsUint, AsReal and AsWhole convert attribute values to numbers. If attribute handle is null or attribute value is empty, 0 is returned. Otherwise, all leading whitespace characters are truncated, and the remaining string is parsed as a decimal number (AsInt, AsUint or AsWhole) or as a floating point number in either decimal or scientific form (AsDouble, AsFloat or AsReal). Any extra characters are silently discarded, i.e. AsInt will return 1 for string "1abc".
In case the input string contains a number that is out of the target numeric range, the result is undefined.
AsBool converts attribute value to boolean as follows: if attribute handle is null or attribute value is empty, false is returned. Otherwise, true is returned if the first character is one of '1', 't', 'T', 'y', 'Y'. This means that strings like "true" and "yes" are recognized as true, while strings like "false" and "no" are recognized as false. For more complex matching you'll have to write your own function.
This is an example of using these functions, along with node data retrieval ones:
Since a lot of document traversal consists of finding the node/attribute with the correct name, there are special functions for that purpose:
GetChild and GetAttribute return the first child/attribute with the specified name; GetNextSibling and GetPreviousSibling return the first sibling in the corresponding direction with the specified name. All string comparisons are case-sensitive. In case the node handle is null or there is no node/attribute with the specified name, null handle is returned.
GetChild and GetNextSibling functions can be used together to loop through all child nodes with the desired name like this:
Occasionally the needed node is specified not by the unique name but instead by the value of some attribute; for example, it is common to have node collections with each node having a unique id: <group> <item id="1"/> <item id="2"/> </group>. There are two functions for finding child nodes based on the attribute values:
The three-argument function returns the first child node with the specified name which has an attribute with the specified name/value; the two-argument function skips the name test for the node, which can be useful for searching in heterogeneous collections. If the node handle is null or if no node is found, null handle is returned. All string comparisons are case-sensitive.
In all of the above functions, all arguments have to be valid strings; passing null pointers results in undefined behavior.
This is an example of using these functions:
Child node lists and attribute lists are simply double-linked lists; while you can use GetPreviousSibling/GetNextSibling and other such functions for iteration, Mezzanine::xml additionally provides node and attribute iterators, so that you can treat nodes as containers of other nodes or attributes:
begin and attributes_begin return iterators that point to the first node/attribute, respectively; end and attributes_end return past-the-end iterator for node/attribute list, respectively - this iterator can't be dereferenced, but decrementing it results in an iterator pointing to the last element in the list (except for empty lists, where decrementing past-the-end iterator results in undefined behavior). Past-the-end iterator is commonly used as a termination value for iteration loops (see sample below). If you want to get an iterator that points to an existing handle, you can construct the iterator with the handle as a single constructor argument, like so: Mezzanine::XML::NodeIterator(node). For Mezzanine::XML::AttributeIterator, you'll have to provide both an attribute and its parent node.
begin and end return equal iterators if called on null node; such iterators can't be dereferenced. attributes_begin and attributes_end behave the same way. For correct iterator usage this means that child node/attribute collections of null nodes appear to be empty.
Both types of iterators have bidirectional iterator semantics (i.e. they can be incremented and decremented, but efficient random access is not supported) and support all usual iterator operations - comparison, dereference, etc. The iterators are invalidated if the node/attribute objects they're pointing to are removed from the tree; adding nodes/attributes does not invalidate any iterators.
Here is an example of using iterators for document traversal:
The methods described above allow traversal of immediate children of some node; if you want to do a deep tree traversal, you'll have to do it via a recursive function or some equivalent method. However, pugixml provides a helper for depth-first traversal of a subtree. In order to use it, you have to implement the Mezzanine::XML::TreeWalker interface and to call the Mezzanine::XML::Node::Traverse function.
The traversal is launched by calling traverse function on traversal root and proceeds as follows:
If begin, end or any of the for_each calls return false, the traversal is terminated and false is returned as the traversal result; otherwise, the traversal results in true. Note that you don't have to override begin or end functions; their default implementations return true.
You can get the node's depth relative to the traversal root at any point by calling TreeWalker::Depth function. It returns -1 if called from begin/end, and returns 0-based depth if called from TreeWalker::for_each - depth is 0 for all children of the traversal root, 1 for all grandchildren and so on.
This is an example of traversing tree hierarchy with Mezzanine::XML::TreeWalker:
While there are existing functions for getting a node/attribute with known contents, they are often not sufficient for simple queries. As an alternative for manual iteration through nodes/attributes until the needed one is found, you can make a predicate and call one of Find functions:
The predicate should be either a plain function or a function object which accepts one argument of type Mezzanine::XML::Attribute (for FindAttribute) or Mezzanine::XML::Node (for FindChild and FindNode), and returns bool. The predicate is never called with null handle as an argument.
Mezzanine::XML::Node::FindAttribute function iterates through all attributes of the specified node, and returns the first attribute for which the predicate returned true. If the predicate returned false for all attributes or if there were no attributes (including the case where the node is null), null attribute is returned.
Mezzanine::XML::Node::FindChild function iterates through all child nodes of the specified node, and returns the first node for which the predicate returned true. If the predicate returned false for all nodes or if there were no child nodes (including the case where the node is null), null node is returned.
Mezzanine::XML::Node::FindNode function performs a depth-first traversal through the subtree of the specified node (excluding the node itself), and returns the first node for which the predicate returned true. If the predicate returned false for all nodes or if subtree was empty, null node is returned.
Here are some sample predicates:
This is an example of using predicate-based functions:
If you need to get the document root of some node, you can use the following function:
This function returns the node with type NodeDocument, which is the root node of the document the node belongs to (unless the node is null, in which case null node is returned).
While Mezzanine::xml supports complex XPath expressions, sometimes a simple path handling facility is needed. There are two functions, for getting node path and for converting path to a node:
Node paths consist of node names, separated with a delimiter (which is / by default); also paths can contain self (.) and parent (..) pseudo-names, so that this is a valid path: "../../foo/./bar". path returns the path to the node from the document root, FirstElementByPath looks for a node represented by a given path; a path can be an absolute one (absolute paths start with the delimiter), in which case the rest of the path is treated as document root relative, and relative to the given node. For example, in the following document: <a> <b> <c/> </b> </a>, node <c/> has path "a/b/c"; calling FirstElementByPath for document with path "a/b" results in node <b/>; calling FirstElementByPath for node <a/> with path "../a/./b/../." results in node <a/>; calling FirstElementByPath with path "/a" results in node <a/> for any node.
In case path component is ambiguous (if there are two nodes with given name), the first one is selected; paths are not guaranteed to uniquely identify nodes in a document. If any component of a path is not found, the result of FirstElementByPath is null node; also FirstElementByPath returns null node for null nodes, in which case the path does not matter. path returns an empty string for null nodes.
Mezzanine::xml does not record row/column information for nodes upon parsing for efficiency reasons. However, if the node has not changed in a significant way since parsing (the name/value are not changed, and the node itself is the original one, i.e. it was not deleted from the tree and re-added later), it is possible to get the offset from the beginning of XML buffer:
If the offset is not available (this happens if the node is null, was not originally parsed from a stream, or has changed in a significant way), the function returns -1. Otherwise it returns the offset to node's data from the beginning of XML buffer in Mezzanine::XML::char_t units. For more information on parsing offsets, see parsing error handling documentation.
The document in Mezzanine::xml is fully mutable: you can completely change the document structure and modify the data of nodes/attributes. This section provides documentation for the relevant functions. All functions take care of memory management and structural integrity themselves, so they always result in structurally valid tree - however, it is possible to create an invalid XML tree (for example, by adding two attributes with the same name or by setting attribute/node name to empty/invalid string). Tree modification is optimized for performance and for memory consumption, so if you have enough memory you can create documents from scratch with Mezzanine::xml and later save them to file/stream instead of relying on error-prone manual text writing and without too much overhead.
All member functions that change node/attribute data or structure are non-constant and thus can not be called on constant handles. However, you can easily convert constant handle to non-constant one by simple assignment: void foo(const Mezzanine::XML::Node& n) { Mezzanine::XML::Node nc = n; }, so const-correctness here mainly provides additional documentation.
As discussed before, nodes can have name and value, both of which are c-strings. Depending on node type, name or value may be absent. NodeDocument nodes do not have a name or value, NodeElement and NodeDeclaration nodes always have a name but never have a value, NodePcdata, NodeCdata, NodeComment and NodeDocType nodes never have a name but always have a value (it may be empty though), NodePi nodes always have a name and a value (again, value may be empty). In order to set node's name or value, you can use the following functions:
Both functions try to set the name/value to the specified string, and return the operation result. The operation fails if the node can not have name or value (for instance, when trying to call SetName on a NodePcdata node), if the node handle is null, or if there is insufficient memory to handle the request. The provided string is copied into document managed memory and can be destroyed after the function returns (for example, you can safely pass stack-allocated buffers to these functions). The name/value content is not verified, so take care to use only valid XML names, or the document may become malformed.
There is no equivalent of ChildValue function for modifying text children of the node.
This is an example of setting node name and value:
All attributes have name and value, both of which are strings (value may be empty). You can set them with the following functions:
Both functions try to set the name/value to the specified string, and return the operation result. The operation fails if the attribute handle is null, or if there is insufficient memory to handle the request. The provided string is copied into document managed memory and can be destroyed after the function returns (for example, you can safely pass stack-allocated buffers to these functions). The name/value content is not verified, so take care to use only valid XML names, or the document may become malformed.
In addition to string functions, several functions are provided for handling attributes with numbers and booleans as values:
The above functions convert the argument to string and then call the base SetValue function. Integers are converted to a decimal form, floating-point numbers are converted to either decimal or scientific form, depending on the number magnitude, boolean values are converted to either "true" or "false".
For convenience, all set_value functions have the corresponding assignment operators:
These operators simply call the right SetValue function and return the attribute they're called on; the return value of SetValue is ignored, so errors are ignored.
This is an example of setting attribute name and value:
Nodes and attributes do not exist without a document tree, so you can't create them without adding them to some document. A node or attribute can be created at the end of node/attribute list or before/after some other node:
AppendAttribute and AppendChild create a new node/attribute at the end of the corresponding list of the node the method is called on; PrependAttribute and PrependChild create a new node/attribute at the beginning of the list; InsertAttributeAfter, InsertAttributeBefore, InsertChildAfter and InsertAttributeBefore add the node/attribute before or after the specified node/attribute.
The overloads of AppendChild and PrependChild that accept Mezzanine::String references convert it to a string, then call the version of the function that accepts a c-style string.
Attribute functions create an attribute with the specified name; you can specify the empty name and change the name later if you want to. Node functions with the type argument create the node with the specified type; since node type can't be changed, you have to know the desired type beforehand. Also note that not all types can be added as children; see below for clarification. Node functions with the name argument create the element node (NodeElement) with the specified name.
All functions return the handle to the created object on success, and null handle on failure. There are several reasons for failure:
Even if the operation fails, the document remains in consistent state, but the requested node/attribute is not added.
This is an example of adding new attributes/nodes to the document:
If you do not want your document to contain some node or attribute, you can remove it with one of the following functions:
RemoveAttribute removes the attribute from the attribute list of the node, and returns the operation result. RemoveChild removes the child node with the entire subtree (including all descendant nodes and attributes) from the document, and returns the operation result. Removing fails if one of the following is true:
Removing the attribute or node invalidates all handles to the same underlying object, and also invalidates all iterators pointing to the same object. Removing node also invalidates all past-the-end iterators to its attribute or child node list. Be careful to ensure that all such handles and iterators either do not exist or are not used after the attribute/node is removed.
If you want to remove the attribute or child node by its name, two additional helper functions are available:
These functions look for the first attribute or child with the specified name, and then remove it, returning the result. If there is no attribute or child with such name, the function returns false; if there are two nodes with the given name, only the first node is deleted. If you want to delete all nodes with the specified name, you can use code like this: while (node.RemoveChild("tool")) ;.
This is an example of removing attributes/nodes from the document:
With the help of previously described functions, it is possible to create trees with any contents and structure, including cloning the existing data. However since this is an often needed operation, Mezzanine::xml provides built-in node/attribute cloning facilities. Since nodes and attributes do not exist without a document tree, you can't create a standalone copy
These functions mirror the structure of AppendChild, PrependChild, InsertChildBefore and related functions - they take the handle to the prototype object, which is to be cloned, insert a new attribute/node at the appropriate place, and then copy the attribute data or the whole node subtree to the new object. The functions return the handle to the resulting duplicate object, or null handle on failure.
The attribute is copied along with the name and value; the node is copied along with its type, name and value; additionally attribute list and all children are recursively cloned, resulting in the deep subtree clone. The prototype object can be a part of the same document, or a part of any other document.
The failure conditions resemble those of AppendChild, InsertChild_before and related functions, consult their documentation for more information. There are additional caveats specific to cloning functions:
This is an example with one possible implementation of include tags in XML. It illustrates node cloning and usage of other document modification functions:
Often after creating a new document or loading the existing one and processing it, it is necessary to save the result back to file. Also it is occasionally useful to output the whole document or a subtree to some stream; use cases include debug printing, serialization via network or other text-oriented medium, etc. Mezzanine::xml provides several functions to output any subtree of the document to a file, stream or another generic transport interface; these functions allow one to customize the output format ( see Output Options ), and also perform necessary encoding conversions ( see Encodings ). This section documents the relevant functionality.
Before writing to the destination the node/attribute data is properly formatted according to the node type; all special XML symbols, such as < and &, are properly escaped. In order to guard against forgotten node/attribute names, empty node/attribute names are printed as ":anonymous". For well-formed output, make sure all node and attribute names are set to meaningful values.
CDATA sections with values that contain "]]>" are split into several sections as follows: section with value "pre]]>post" is written as <![CDATA[pre]]]]><![CDATA[>post]]>. While this alters the structure of the document (if you load the document after saving it, there will be two CDATA sections instead of one), this is the only way to escape CDATA contents.
If you want to save the whole document to a file, you can use one of the following functions:
These functions accept file path as its first argument, and also three optional arguments, which specify indentation and other output options (see Output options) and output data encoding ( see @ ref XMLSavingEncodings ). The Path has the target operating system format, so it can be a relative or absolute one, it should have the delimiters of the target system, it should have the exact case if the target file system is case-sensitive, etc.
File path is passed to the system file opening function as is in case of the first function (which accepts const char* Path); the second function either uses a special file opening function if it is provided by the runtime library or converts the path to UTF-8 and uses the system file opening function.
SaveFile opens the target file for writing, outputs the requested header (by default a document declaration is output, unless the document already has one), and then saves the document contents. If the file could not be opened, the function returns false. Calling SaveFile is equivalent to creating an Mezzanine::XML::WriterFile object with FILE* handle as the only constructor argument and then calling save; see Saving Document via Writer Interface for writer interface details.
This is a simple example of saving XML document to a file :
To enhance interoperability Mezzanine::xml provides functions for saving document to any object which implements C++ std::ostream interface. This allows you to save documents to any standard C++ stream (i.e. file stream) or any third-party compliant implementation (i.e. Boost Iostreams). Most notably, this allows for easy debug output, since you can use std::cout stream as saving target. There are two functions, one works with narrow character streams, another handles wide character ones:
Calling Save with an std::ostream argument saves the document to the stream in the same way as SaveFile (i.e. with requested header and with encoding conversions). On the other hand, save with std::wstream argument saves the document to the wide stream with Encoding::Encodingwchar_t encoding. Because of this, using save with wide character streams requires careful (usually platform-specific) stream setup (i.e. using the imbue function). Generally use of wide streams is discouraged, however it provides you with the ability to save documents to non-Unicode encodings, i.e. you can save Shift-JIS encoded data if you set the correct locale.
Calling Save with stream target is equivalent to creating an Mezzanine::XML::WriterStream object with stream as the only constructor argument and then calling save; see Saving Document via Writer Interface for writer interface details.
This is a simple example of saving XML document to standard output:
All of the above saving functions are implemented in terms of the Mezzanine::XML::Writer interface. This is a simple interface with a single function, which is called several times during output process with chunks of document data as input.
In order to output the document via some custom transport, for example sockets, you should create an object which implements Mezzanine::XML::Writer interface and pass it to save function. Mezzanine::XML::Writer::Write function is called with a buffer as an input, where data points to buffer start, and size is equal to the buffer size in bytes. The Write implementation must write the buffer to the transport; it can not save the passed buffer pointer, as the buffer contents will change after write returns. The buffer contains the chunk of document data in the desired encoding.
The Write function is called with relatively large blocks (size is usually several kilobytes, except for the first block with BOM, which is output only if Mezzanine::XML::FormatWriteBom is set, and last block, which may be small), so there is often no need for additional buffering in the implementation.
This is a simple example of custom writer for saving document data to STL string:
While the previously described functions save the whole document to the destination, it is easy to save a single subtree. The following functions are provided:
These functions have the same arguments with the same meaning as the corresponding Mezzanine::XML::Document::Save functions, and allow you to save the subtree to either a C++ IOstream or to any object that implements Mezzanine::XML::Writer interface.
Saving a subtree differs from saving the whole document: the process behaves as if Mezzanine::XML::FormatWriteBom is off, and Mezzanine::XML::FormatNoDeclaration is on, even if actual values of the flags are different. This means that BOM is not written to the destination, and document declaration is only written if it is the node itself or is one of node's children. Note that this also holds if you're saving a document; this example illustrates the difference:
All saving functions accept the optional parameter flags. This is a bitmask that customizes the output format; you can select the way the document nodes are printed and select the needed additional information that is output before the document contents.
These flags control the resulting tree contents:
These flags control the additional output information:
Additionally, there is one predefined option mask:
Mezzanine::xml supports all popular Unicode encodings (UTF-8, UTF-16 (big and little endian), UTF-32 (big and little endian); UCS-2 is naturally supported since it's a strict subset of UTF-16) and handles all encoding conversions during output. The output encoding is set via the encoding parameter of saving functions, which is of type xml_encoding. The possible values for the encoding are documented in Encodings; the only flag that has a different meaning is EncodingAuto.
While all other flags set the exact encoding, EncodingAuto is meant for automatic encoding detection. The automatic detection does not make sense for output encoding, since there is usually nothing to infer the actual encoding from, so here EncodingAuto means UTF-8 encoding, which is the most popular encoding for XML data storage. This is also the default value of output encoding; specify another value if you do not want UTF-8 encoded output.
Also note that wide stream saving functions do not have encoding argument and always assume Encodingwchar_t encoding.
If the task at hand is to select a subset of document nodes that match some criteria, it is possible to code a function using the existing traversal functionality for any practical criteria. However, often either a data-driven approach is desirable, in case the criteria are not predefined and come from a file, or it is inconvenient to use traversal interfaces and a higher-level Domain Specific Language is required. There is a standard language for XML processing, XPath, that can be useful for these cases. Mezzanine::xml implements an almost complete subset of XPath 1.0. Because of differences in document object model and some performance implications, there are minor violations of the official specifications, which can be found in Conformance to W3C Specification . The rest of this section describes the interface for XPath functionality. Please note that if you wish to learn to use XPath language, you have to look for other tutorials or manuals.
Each XPath expression can have one of the following types: boolean, number, string or node set. Boole type corresponds to bool type, number type corresponds to double type, string type corresponds to either std::string or std::wstring, depending on whether wide character interface is enabled, and node set corresponds to Mezzanine::XML::XPathNodeSet type. There is an enumeration, Mezzanine::XML::XPathValueType, which can take the values XPathTypeBoole, XPathTypeNumber, Mezzanine::XML::XPathValueType XPathTypeString or Mezzanine::XML::XPathValueType XPathTypeNodeSet, accordingly.
Because an XPath node can be either a node or an attribute, there is a special type, Mezzanine::XML::XPathNode, which is a discriminated union of these types. A value of this type contains two node handles, one of Mezzanine::XML::Node type, and another one of Mezzanine::XML::Attribute type; at most one of them can be non-null. The accessors to get these handles are available:
XPath nodes can be null, in which case both accessors return null handles.
Note that as per XPath specification, each XPath node has a parent, which can be retrieved via this function:
The GetParent function returns the node's parent if the XPath node corresponds to Mezzanine::XML::Node handle (equivalent to GetNode().GetParent()), or the node to which the attribute belongs to, if the XPath node corresponds to Mezzanine::XML::Attribute handle. For null nodes, parent returns null handle.
Like node and attribute handles, XPath node handles can be implicitly cast to boolean-like object to check if it is a null node, and also can be compared for equality with each other.
You can also create XPath nodes with one of the three constructors: the default constructor, the constructor that takes node argument, and the constructor that takes an attribute and a node argument (in which case the attribute must belong to the attribute list of the node). The constructor from Mezzanine::XML::Node is implicit, so you can usually pass Mezzanine::XML::Node to functions that expect Mezzanine::XML::XPathNode. Apart from that you usually don't need to create your own XPath node objects, since they are returned to you via selection functions.
XPath expressions operate not on single nodes, but instead on node sets. A node set is a collection of nodes, which can be optionally ordered in either a forward document order or a reverse one. Document order is defined in XPath specification; an XPath node is before another node in document order if it appears before it in XML representation of the corresponding document.
Node sets are represented by Mezzanine::XML::XPathNodeSet object, which has an interface that resembles one of sequential random-access containers. It has an iterator type along with usual begin/past-the-end iterator accessors:
And it also can be iterated via indices, just like std::vector:
All of the above operations have the same semantics as that of std::vector: the iterators are random-access, all of the above operations are constant time, and accessing the element at index that is greater or equal than the set size results in undefined behavior. You can use both iterator-based and index-based access for iteration, however the iterator-based one can be faster.
The order of iteration depends on the order of nodes inside the set; the order can be queried via the following function:
The Type function returns the current order of nodes; TypeSorted means that the nodes are in forward document order, TypeSortedReverse means that the nodes are in reverse document order, and TypeUnsorted means that neither order is guaranteed (nodes can accidentally be in a sorted order even if Type() returns TypeUnsorted). If you require a specific order of iteration, you can change it via sort function: void Mezzanine::XML::XPathNodeSet::sort(bool reverse = false);
Calling sort sorts the nodes in either forward or reverse document order, depending on the argument; after this call Type() will return TypeSorted or TypeSortedReverse.
Often the actual iteration is not needed; instead, only the first element in document order is required. For this, a special accessor is provided:
This function returns the first node in forward document order from the set, or null node if the set is empty. Note that while the result of the node does not depend on the order of nodes in the set (i.e. on the result of Type()), the complexity does - if the set is sorted, the complexity is constant, otherwise it is linear in the number of elements or worse.
While in the majority of cases the node set is returned by XPath functions, sometimes there is a need to manually construct a node set. For such cases, a constructor is provided which takes an iterator range (const_iterator is a typedef for const Mezzanine::XML::XPathNode*), and an optional type:
The constructor copies the specified range and sets the specified type. The objects in the range are not checked in any way; you'll have to ensure that the range contains no duplicates, and that the objects are sorted according to the type parameter. Otherwise XPath operations with this set may produce unexpected results.
If you want to select nodes that match some XPath expression, you can do it with the following functions:
The FindNodes function compiles the expression and then executes it with the node as a context node, and returns the resulting node set. FindSingleNode returns only the first node in document order from the result, and is equivalent to calling FindNodes(query).first(). If the XPath expression does not match anything, or the node handle is null, FindNodes returns an empty set, and FindSingleNode returns null XPath node.
Both functions throw Mezzanine::XML::XPathException if the query can not be compiled or if it returns a value with type other than node set; see Error handling for details.
While compiling expressions is fast, the compilation time can introduce a significant overhead if the same expression is used many times on small subtrees. If you're doing many similar queries, consider compiling them into query objects (see Using Query Objects for further reference). Once you get a compiled query object, you can pass it to Find functions instead of an expression string:
Both functions throw Mezzanine::XML::XPathException if the query returns a value with type other than node set.
This is an example of selecting nodes using XPath expressions:
When you call FindNodes with an expression string as an argument, a query object is created behind the scenes. A query object represents a compiled XPath expression. Query objects can be useful in the following circumstances:
Query objects correspond to Mezzanine::XML::XPathQuery type. They are immutable and non-copyable: they are bound to the expression at creation time and can not be cloned. If you want to put query objects in a container, allocate them on heap via new operator and store pointers to Mezzanine::XML::XPathQuery in the container.
You can create a query object with the constructor that takes XPath expression as an argument:
The expression is compiled and the compiled representation is stored in the new query object. If compilation fails, XPathException is thrown if exception handling is not disabled (see Error Handling for details). After the query is created, you can query the type of the evaluation result using the following function:
You can evaluate the query using one of the following functions:
All functions take the context node as an argument, compute the expression and return the result, converted to the requested type. According to XPath specification, value of any type can be converted to boolean, number or string value, but no type other than node set can be converted to node set. Because of this, EvaluateBoole, EvaluateNumber and EvaluateString always return a result, but EvaluateNodeSet results in an error if the return type is not node set ( see Error Handling ).
There is another string evaluation function:
This function evaluates the string, and then writes the result to buffer (but at most capacity characters); then it returns the full size of the result in characters, including the terminating zero. If capacity is not 0, the resulting buffer is always zero-terminated. You can use this function as follows:
This is an example of using query objects:
XPath queries may contain references to variables; this is useful if you want to use queries that depend on some dynamic parameter without manually preparing the complete query string, or if you want to reuse the same query object for similar queries.
Variable references have the form $name; in order to use them, you have to provide a variable set, which includes all variables present in the query with correct types. This set is passed to Mezzanine::XML::XPathQuery constructor or to FindNodes/FindNode functions:
If you're using query objects, you can change the variable values before evaluate/select calls to change the query behavior.
Variable sets correspond to XPathVariableSet type, which is essentially a variable container.
You can add new variables with the following function:
The function tries to add a new variable with the specified name and type; if the variable with such name does not exist in the set, the function adds a new variable and returns the variable handle; if there is already a variable with the specified name, the function returns the variable handle if variable has the specified type. Otherwise the function returns null pointer; it also returns null pointer on allocation failure.
New variables are assigned the default value which depends on the type: 0 for numbers, false for booleans, empty string for strings and empty set for node sets.
You can get the existing variables with the following functions:
The functions return the variable handle, or null pointer if the variable with the specified name is not found.
Additionally, there are the helper functions for setting the variable value by name; they try to add the variable with the corresponding type, if it does not exist, and to set the value. If the variable with the same name but with different type is already present, they return false; they also return false on allocation failure. Note that these functions do not perform any type conversions.
The variable values are copied to the internal variable storage, so you can modify or destroy them after the functions return.
If setting variables by name is not efficient enough, or if you have to inspect variable information or get variable values, you can use variable handles. A variable corresponds to the XPathVariable type, and a variable handle is simply a pointer to XPathVariable.
In order to get variable information, you can use one of the following functions:
Note that each variable has a distinct type which is specified upon variable creation and can not be changed later.
In order to get variable value, you should use one of the following functions, depending on the variable type:
These functions return the value of the variable. Note that no type conversions are performed; if the type mismatch occurs, a dummy value is returned (false for booleans, NaN for numbers, empty string for strings and empty set for node sets).
In order to set variable value, you should use one of the following functions, depending on the variable type:
These functions modify the variable value. Note that no type conversions are performed; if the type mismatch occurs, the functions return false; they also return false on allocation failure. The variable values are copied to the internal variable storage, so you can modify or destroy them after the functions return.
This is an example of using variables in XPath queries:
There are two different mechanisms for error handling in XPath implementation; the mechanism used depends on whether exception support is disabled (this is controlled with XML_NO_EXCEPTIONS define).
By default, XPath functions throw Mezzanine::XML::XPathException object in case of errors; additionally, in the event any memory allocation fails, an std::bad_alloc exception is thrown. Also Mezzanine::XML::XPathException is thrown if the query is evaluated to a node set, but the return type is not node set. If the query constructor succeeds (i.e. no exception is thrown), the query object is valid. Otherwise you can get the error details via one of the following functions:
If exceptions are disabled, then in the event of parsing failure the query is initialized to invalid state; you can test if the query object is valid by using it in a boolean expression: if (query) { ... }. Additionally, you can get parsing result via the Result() accessor:
Without exceptions, evaluating invalid query results in false, empty string, NaN or an empty node set, depending on the type; evaluating a query as a node set results in an empty node set if the return type is not node set.
The information about parsing result is returned via Mezzanine::XML::XPathParseResult object. It contains parsing status and the offset of last successfully parsed character from the beginning of the source stream.
Parsing result is represented as the error message; it is either a null pointer, in case there is no error, or the error message in the form of ASCII zero-terminated string.
The Description() member function can be used to get the error message; it never returns the null pointer, so you can safely use Description() even if query parsing succeeded.
In addition to the error message, parsing result has an OffSet member, which contains the offset of last successfully parsed character. This offset is in units of Mezzanine::XML::char_t (bytes for character mode, wide characters for wide character mode).
Parsing result object can be implicitly converted to bool like this: if (result) { ... } else { ... }.
This is an example of XPath error handling:
Because of the differences in document object models, performance considerations and implementation complexity, pugixml does not provide a fully conformant XPath 1.0 implementation. This is the current list of incompatibilities:
 1.8.9.1. Thanks to the
Open Icon Library
for help with some of the icons.
1.8.9.1. Thanks to the
Open Icon Library
for help with some of the icons.

